

By Bernard Chen
The ancient beverage, wine, has remained popular in modern times. While the ancients had mostly wine available from neighboring vineyards, the number and variety of wines available for purchase have exploded in modern times. Consumers are assaulted with an endless number of varieties and flavors. Some examples include red wine, white wine, rose wine, starch-based wine, etc., which are then also based on a variety of grapes, fruits like apples, and berries. For a non-expert, unfamiliar with the various nuances that make each brand distinct, the complexity of decision making has vastly increased. In such a competitive market, wine reviews and rankings matter a lot since they become part of the heuristics that drive consumer’s decision making.
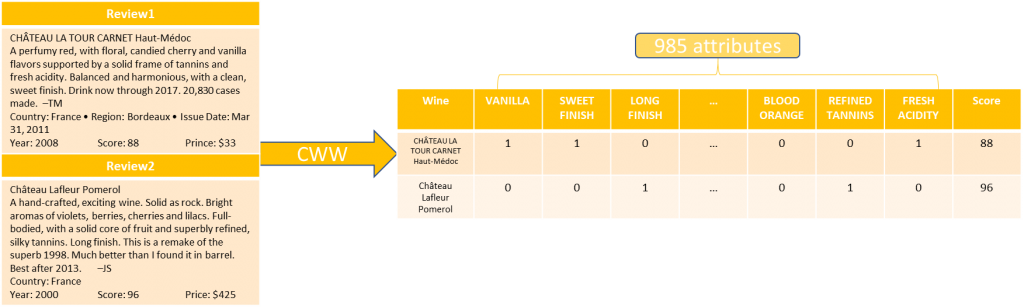
Wineinformatics was proposed that incorporated data science and wine related datasets, including physicochemical laboratory data and wine reviews to discover useful information for wine producers, distributors, and consumers. Wine reviews are produced by sommeliers, people who specialize in wine. These wine reviews usually include aroma, flavors, tannins, weight, finish, appearance, and the interactions related to these wine sensations. For computer perspective, the physicochemical laboratory data is easy to read and apply analytics to, while wine reviews’ data involves natural language processing and a degree of human bias. A new technique named the Computational Wine Wheel was developed to accurately capture keywords, including not only flavors but also non-flavor notes, which always appear in the wine reviews.
Since the wine reviews are stored in human language format, we have to convert reviews into machine understandable via the computational wine wheel. The computational wine wheel works as a dictionary to one-hot encoding to convert words into vectors. For example, in the wine review, there are some words that contain fruits such as apple, blueberry, plum, etc. If the word matches the attribute in the computation wine wheel, it will be 1, otherwise, it will be 0. More examples can be found in Figure 1. Many other wine characteristics are included in the computational wine wheel other than fruit flavors, such as descriptive adjectives (balance, beautifully, etc.) and body of the wine (acidity, level of tannin, etc.). The computational wine wheel is also equipped with generalization function to generalize similar words into the same coding. For example, fresh apple, apple, and ripe apple are generalized into “Apple” since they represent the same flavor; yet, green apple belongs to “Green Apple” since the flavor of green apple is different from apple. The score of the wine is also attached to the data as the last attribute, also known as the label. For supervised learning, in order to understand the characteristics of classic (95+) and outstanding (90–94) wine, we use 90 points as a cutting point. If a wine receives a score equal/above 90 points out of 100, we mark the label as a positive (+) class to the wine. Otherwise, the label would be a negative (−) class. There are some wines that scored a ranged score, such as 85–88. We use the average of the ranged score to decide and assign the label.
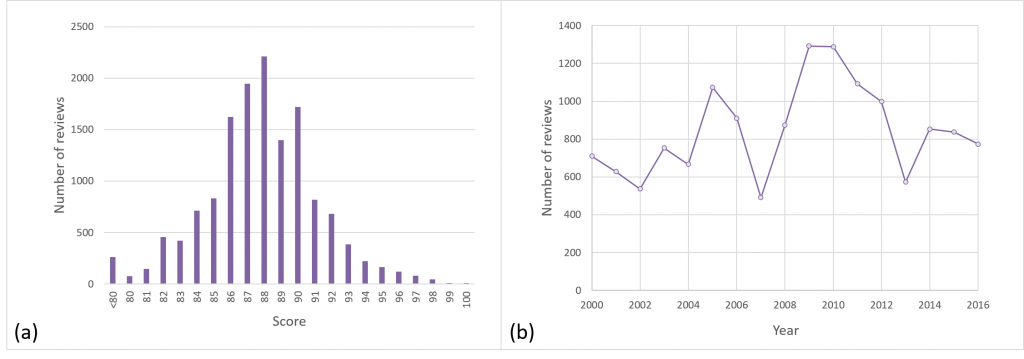
To understand 21st century Bordeaux wines, we collect all available Bordeaux wine reviews from year 2000 ~ 2016 in Wine Spectator. A total of 14,349 Bordeaux wines have been collected and processed through the Computational Wine Wheel. There are 4263 90+ wines and 10,086 89− wines. The number of 89− wines is more than 90+ wines. The score distribution is given in Figure 2a. Most wines score between 86 and 90. Therefore, they fall into the category of “Very Good” wine. In Figure 2b, the line chart is used to represent the trend of number of wines has been reviewed in each year. The chart also reflects the quality of vintages. More than 1200 wines were reviewed in 2009 and 2010, which indicates that 2009 and 2010 are good vintages in Bordeaux. Wine makers are more willing to send their wines to be reviewed if their wines are good.
We trained the Naïve Bayes classification algorithm on the dataset using 5-fold cross validation. The model build from the method archives 85.17% accuracy to predict if a wine can score above 90 points based on the wine review description. The satisfactory results suggest that the Naïve Bayes algorithm can capture important attributes in wine reviews to determine the quality of the wine. Table 1 lists the common keywords represent the important wine characteristics/attributes toward 21st century general Bordeaux wines.
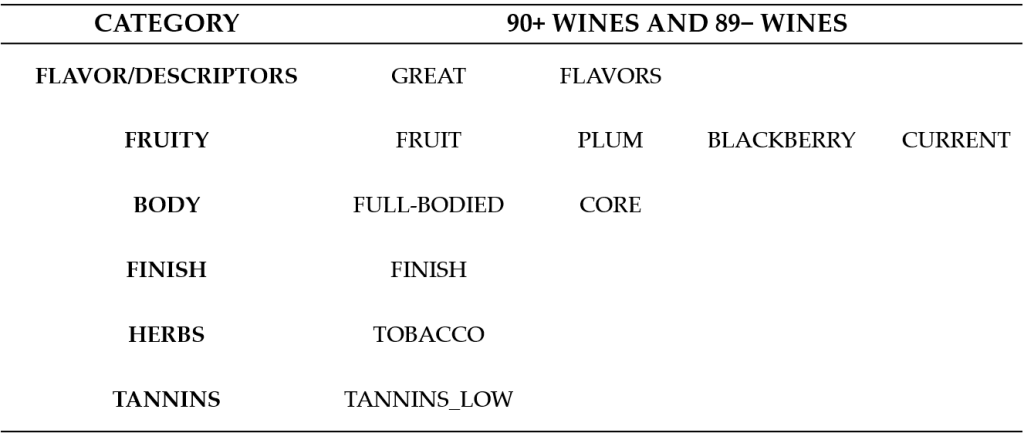
Furthermore, our goal is to understand the important wine characteristics/attributes toward 21st century classic and outstanding Bordeaux wines. Therefore, finding out the distinct keywords between 90+ and 89− is our final goal. Details about the distinct keywords between 90+ and 89− from ALL Bordeaux Wine dataset can be found in Tables 2 and 3.
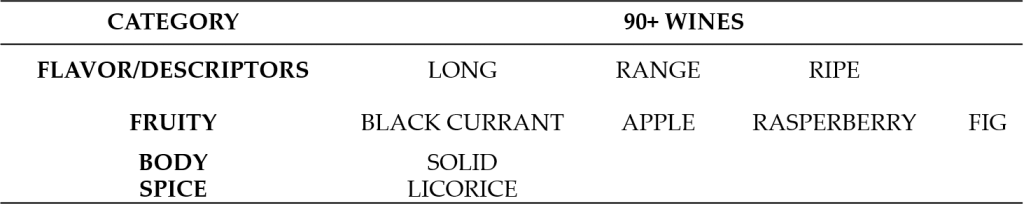

With the benefit of using Naïve Bayes classifier, we were able to find the important wine characteristics/attributes toward 21st century classic and outstanding Bordeaux wines. The list of common attributes in Tables 1 identifies the general wine characteristics in Bordeaux; while the list of dominate attributes in Tables 2 and 3 shows the preferable characteristics for 90+ (90–) wines. Those characteristics/attributes can help producers improve the quality of their wines allowing them to concentrate of dilute the wanted or unwanted characteristics during the wine making process. To the best of our knowledge, this is the first paper that gives a detailed analysis in all prestigious Bordeaux wines in the 21st century.
(Detailed information about this research can be found under: https://www.mdpi.com/2306-5710/7/1/3)

Bernard Chen is a full professor of Computer Science department at the University of Central Arkansas, USA. He received his Ph.D. in Computer Science from Georgia State University in 2008. His current research area is focus on Wineinformatics that incorporated data science and wine related datasets, including physicochemical laboratory data and wine reviews to discover useful information for wine producers, distributors, and consumers. He is working on combining data science techniques with wine data to answer some questions like “What makes wine achieve a 90+ rating?”, “What are the common characteristics shared by 90+ Napa Cabernet sauvignon?”, “What the shared similarities are amongst groups of wine?”, “What characteristics differ between wines from France and Italy?” He has published more than 70 peer-reviewed publications in various journals and conferences, including Big Data Mining and Analytics, Fermentation, and Beverages. He is also program committee member in many reputable international conferences, such as BIBM, ICDM, and ICMLA.
[…] Science & Wine: Understanding 21st Century Bordeaux Wines from Wine Reviews Using Naïve Bayes C… […]